
基于CNN的手写数字识别
0.背景
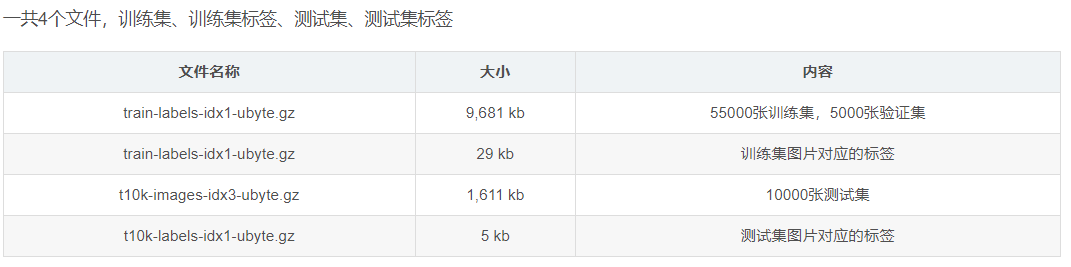
手写数字识别是基于MNIST数据集,将十个数字进行分类。使用Python版本3.10。
MNIST数据集是从NIST的两个手写数字数据集:Special Database 3 和Special Database 1中分别取出部分图像,并经过一些图像处理后得到的。MNIST数据集共有70000张图像,其中训练集60000张,测试集10000张。每张图片是一个28*28像素点的0 ~ 9的灰质手写数字图片,黑底白字,图像像素值为0 ~ 255,越大该点越白。
这是最为经典的机器学习分类问题,实现简单,训练速度快,适合新手入门学习。
MNIST数据集可在http://yann.lecun.com/exdb/mnist/ 获取。
需要准备的库如下。
1 | #%% 导入模块 |
1.数据集
数据集下载1 | #%% 下载数据集 |
1 | ##% 训练数据可视化 |

1 | ##% 测试数据可视化 |

1 | #%% tensorboard |
1 | #%% 制作数据加载器 |
2.模型构建(CNN)
2.0 CNN结构
下图是一个简单的CNN结构图, 第一层输入图片, 进行卷积(Convolution)操作, 得到第二层深度为3的特征图(Feature Map). 对第二层的特征图进行池化(Pooling)操作, 得到第三层深度为3的特征图. 重复上述操作得到第五层深度为5的特征图, 最后将这5个特征图, 也就是5个矩阵, 按行展开连接成向量, 传入全连接(Fully Connected)层, 全连接层就是一个BP神经网络. 图中的每个特征图都可以看成是排列成矩阵形式的神经元, 与BP神经网络中的神经元大同小异。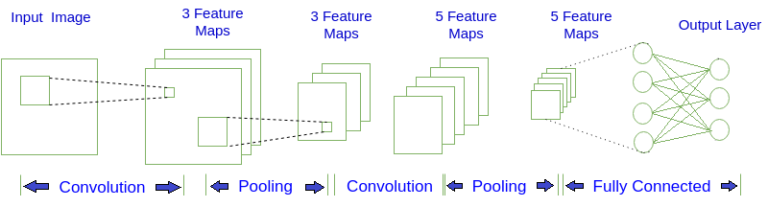
2.1 卷积层
概述每一个卷积核的通道数量要求和输入通道数量一样,卷积核的总数和输出通道的数量一样。
卷积(convolution)后,C(Channels)变。W(Width)和H(Height)可变可不变,取决于填充(padding)。具体操作会在下面介绍。
1 | torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride, padding) |
①in_channels:输入通道
②out_channels:输出通道
③kernel_size:卷积核大小
④stride:步长
⑤padding:填充
卷积(convolution)
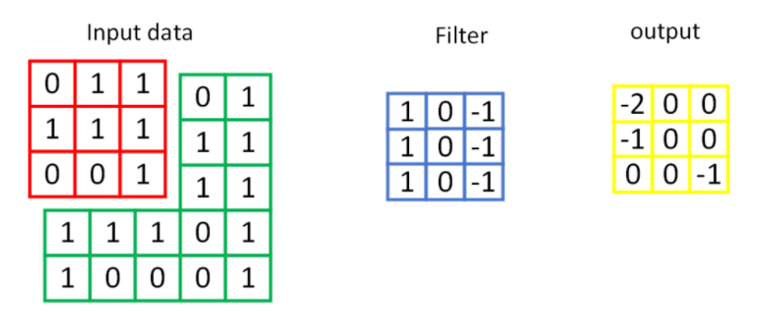
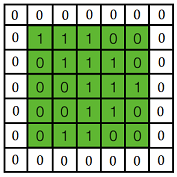
对于一张输入图片, 将其转化为矩阵, 矩阵的元素为对应的像素值. 假设有一个5x5的图像,使用一个3x3的卷积核进行卷积,可得到一个3x3的特征图(特征图和卷积核大小相同只是巧合,如果是4x4的卷积核,则得到2x2的特征图)。卷积核也称为滤波器(Filter)。具体操作如下所示。
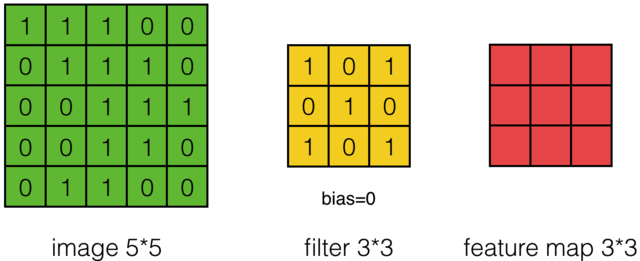
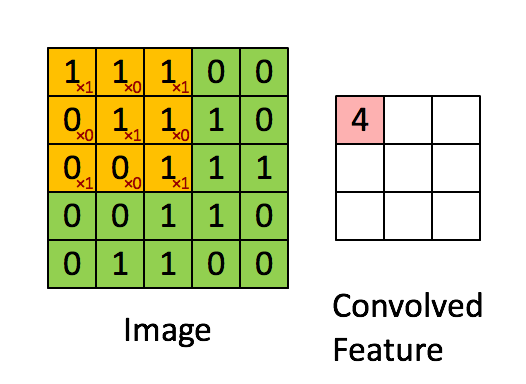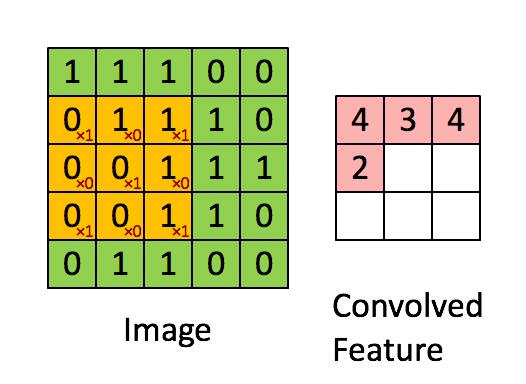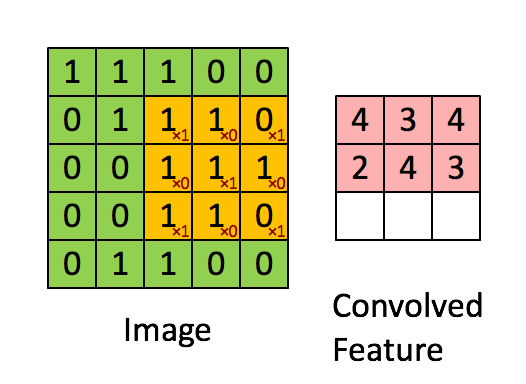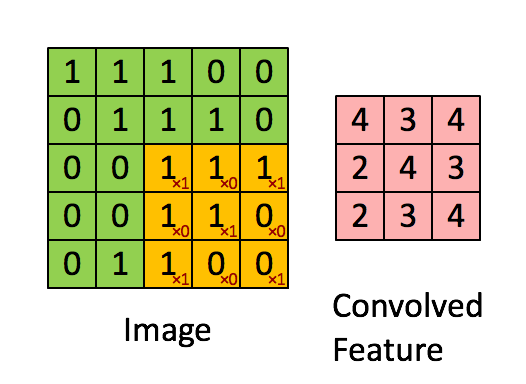
黄色的区域表示卷积核在输入矩阵中滑动,每滑动到一个位置,将对应数字相乘并求和,得到一个特征图矩阵的元素。注意到,动图中卷积核每次滑动了一个单位,实际上滑动的幅度可以根据需要进行调整。如果滑动步幅大于1,则卷积核有可能无法恰好滑到边缘,针对这种情况,可在矩阵最外层补零,补一层零后的矩阵如下图所示。
一般情况下,输入的图片矩阵以及后面的卷积核,特征图矩阵都是方阵,这里设输入矩阵大小为w,卷积核大小为k,步幅为s,补零层数为p,则卷积后产生的特征图大小计算公式为:
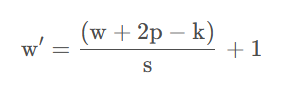
上面介绍的是对一个特征图采用一个卷积核卷积的过程,为了提取更多的特征,可以采用多个卷积核分别进行卷积,这样便可以得到多个特征图。有时,对于一张三通道彩色图片,或者如第三层特征图所示,输入的是一组矩阵,这时卷积核也不再是一层的,而要变成相应的深度。
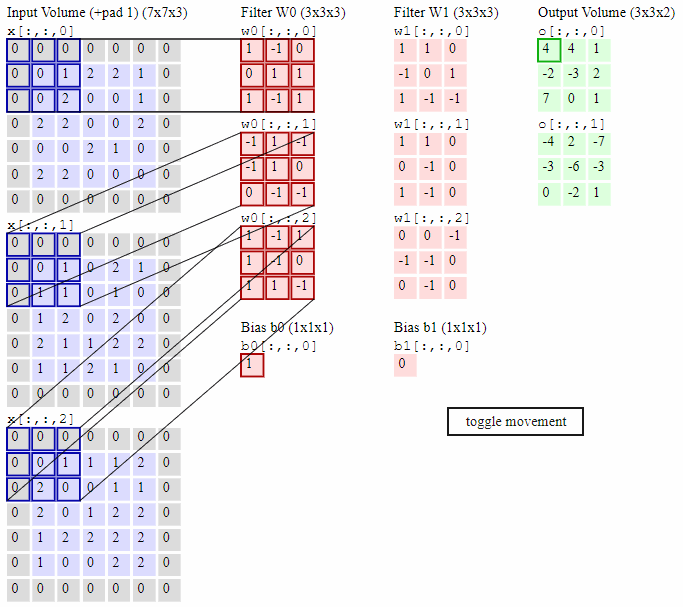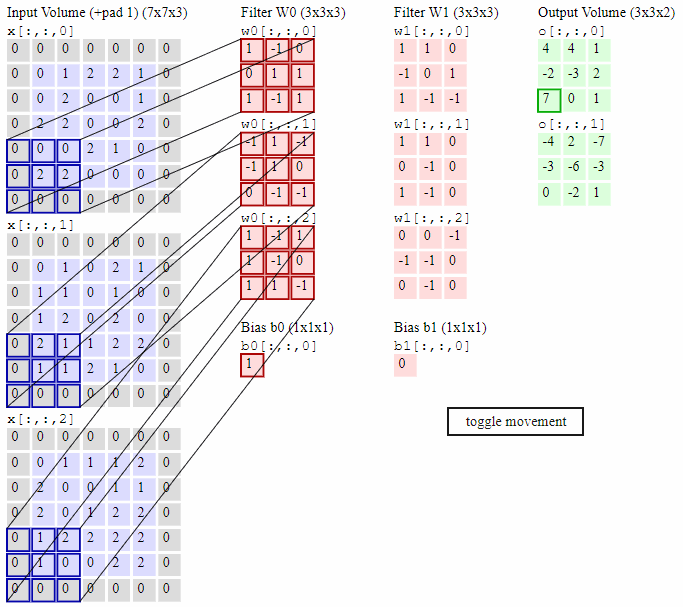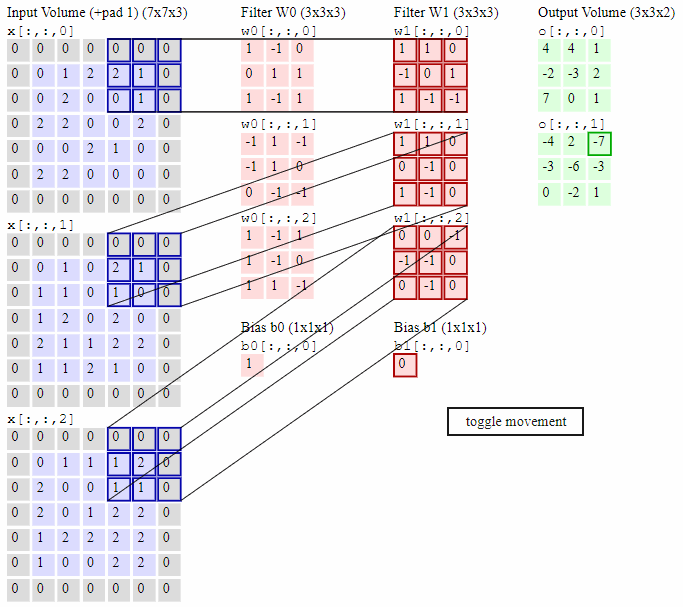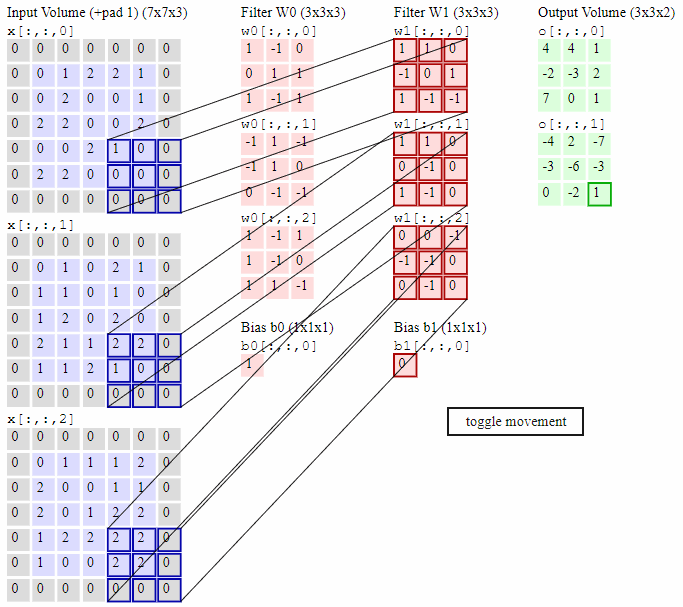
如下图所示,最左边是输入的特征图矩阵,深度为3,补零(Zero Padding)层数为1,每次滑动的步幅为2。中间两列粉色的矩阵分别是两组卷积核,一组有三个,三个矩阵分别对应着卷积左侧三个输入矩阵,每一次滑动卷积会得到三个数,这三个数的和作为卷积的输出。最右侧两个绿色的矩阵分别是两组卷积核得到的特征图。
2.2 激活层
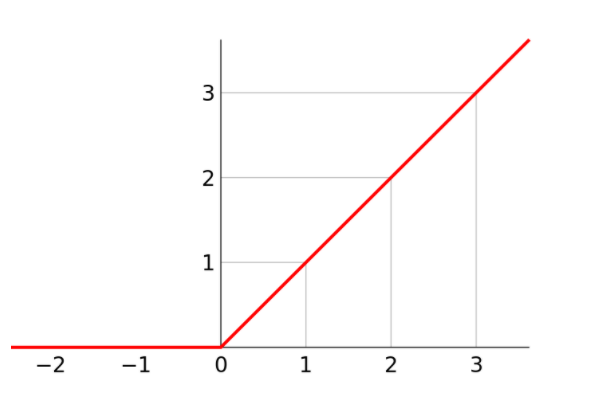
激活层可以选择激活函数(Activation Function),如ReLU, Sigmoid, tanh等。本文采用ReLU激活函数。线性整流函数(Rectified Linear Unit, ReLU),又称修正线性单元,是一种人工神经网络中常用的激活函数(activation function),通常指代以斜坡函数及其变种为代表的非线性函数。
1 | torch.nn.ReLU() |
2.3 池化层
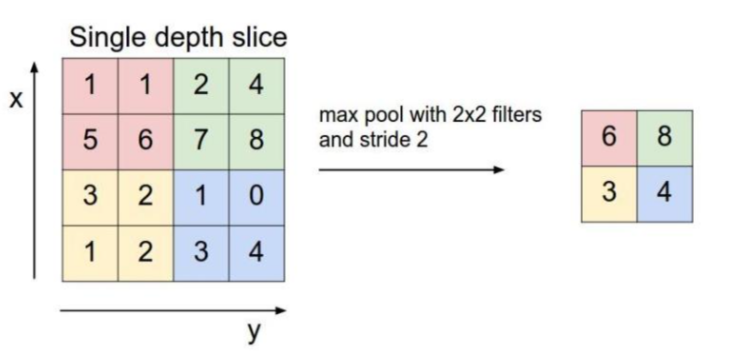
池化又叫下采样(Dwon sampling),与之相对的是上采样(Up sampling)。卷积得到的特征图一般需要一个池化层以降低数据量。池化的操作如下图所示。和卷积一样,池化也有一个滑动的核,可以称之为滑动窗口,上图中滑动窗口的大小为,2x2,步幅为2,每滑动到一个区域,则取最大值作为输出,这样的操作称为Max Pooling、还可以采用输出均值的方式,称为Mean Pooling。
1 | torch.nn.MaxPool2d(input, kernel_size, stride, padding) |
①input:输入
②kernel_size:卷积核大小
③stride:步长
④padding:填充
2.4 全连接层
经过若干层的卷积,池化操作后,将得到的特征图依次按行展开,连接成向量,输入全连接网络。之前卷积层要求输入输出是四维张量(B,C,W,H),而全连接层的输入与输出都是二维张量(B,Input_feature),经过卷积、激活、池化后,使用view打平,进入全连接层。
2.5 CNN整体流程
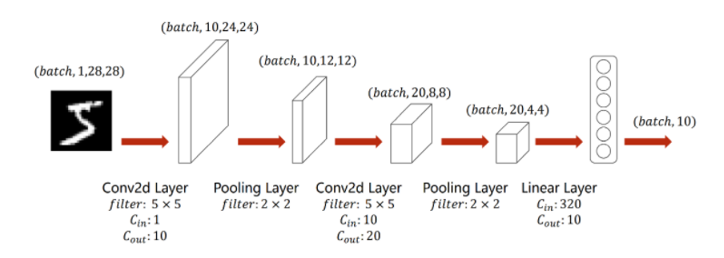
①通过一个卷积核为5×5的卷积层,其通道数从1变为10,高宽分别为24像素。
②通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,10,12,12)。
③通过一个卷积核为5×5的卷积层,其通道数从10变为20,高宽分别为8像素。
④通过一个卷积核为2×2的最大池化层,通道数不变,高宽变为一半,即维度变成(batch,20,4,4)。
⑤将其view展平,使其维度变为320之后进入全连接层,用线性函数将其输出为10类,即”0-9”10个数字。
模型结构代码
1 | #%% 模型结构 |
3.损失函数和优化器
损失函数使用交叉熵损失。参数优化使用随机梯度下降。
1 | #%% 创建模型 |
4.训练
4.1 定义训练过程输出
训练过程如下。①前馈(forward propagation)
②反馈(backward propagation)
③更新(update)
在第一部分数据集的参数定义中,我们设置了训练的轮数(EPOCH)和优化器的学习率(LR)。在训练过程中打印我们需要的信息,保存效果好的模型,代码如下。
1 | #%% 训练过程打印函数 |
4.2 模型训练
训练代码如下。1 | #%% 训练模型 |
4.3 训练结果
整个训练过程到此结束了,训练完成后会保存一个最佳模型。训练过程会输出每轮中训练集和测试集的损失率和准确率以及训练花费的时间,单位为秒。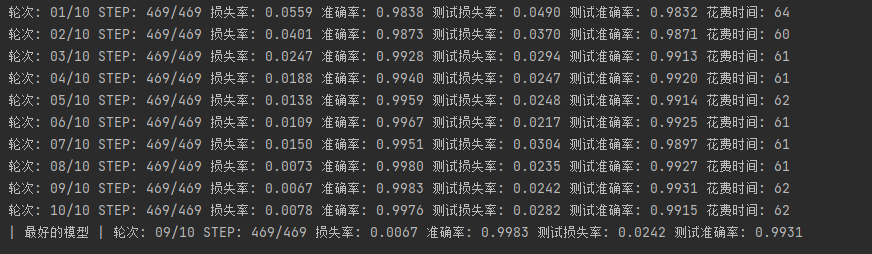
5.测试
5.0 导入库
新建一个新的.py文件。首先导入库,其中model文件在文末有给出,把model.py和test.py放在一个文件夹中就可以了。model.py的内容就是卷积操作的过程,参数要和train中的一样。
1 | #%% 导入模块 |
5.1 数据准备
在当前文件夹中建立一个test的文件夹,并将28*28的png格式的黑底白字的png图片放入文件夹中,图片名字为图中数字,作为标签使用。图片可以用Windows自带的画板工具绘画,设置图片大小为28*28,设置为黑底,用画笔写字。数据加载代码如下。
1 | #%% 数据准备 |
5.2 预测
加载之前训练好保存的模型model.pt,用该模型进行预测,并展示结果。1 | #%% 加载模型 |

6.代码
如下图所示需要准备四个文件,这四个文件在文末都有给出。其中dataset存放MNIST的图片,test存放测试需要的图片,可以自行的增减。train.py是训练模型的代码,test.py是测试用的代码,model.py中存放测试时使用的卷积操作代码,该部分内容需要与train.py中卷积操作的代码一致。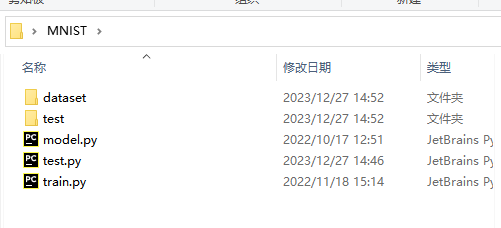
1 | #%% 导入模块 |
1 | import torch.nn as nn |
1 | #%% 数据说明 |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来自 ZzzY Blog!